はじめに
株式会社ネクストスケープ ソリューションビジネス部の小野塚です。
この記事は「NEXTSCAPE Advent Calendar 2024」の3日目の記事となります。
以前Speech Studioのリアルタイム音声テキスト変換を試してみましたが、今回はまた別の機能、「テキスト読み上げアバター」を試してみたいと思います。
導入部分
まずは前回同様Speech Studioにログインし、色々な項目・機能がある中、「テキスト読み上げ」内の「テキスト読み上げアバター」をクリックします。
すると、以下のページが開きます。
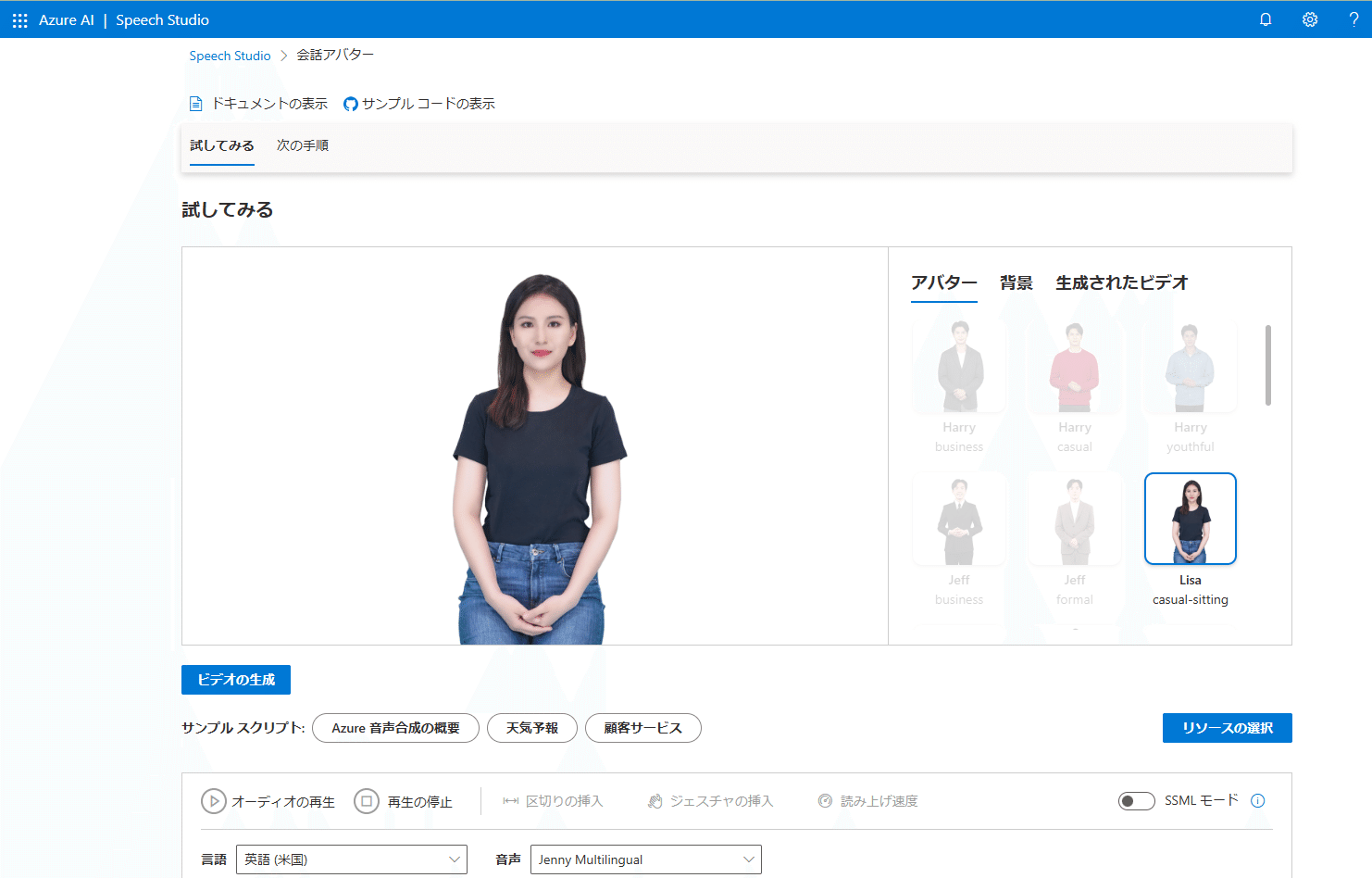
いきなり女性の画像が出てきますが、これが「アバター」となります。
前回の「リアルタイム音声テキスト変換」はAzureポータル側で何かを作成することなく、色々なことが試せましたが、この「テキスト読み上げアバター」についてはAzureサブスクリプションを用意し、そのサブスクリプション上に「Speech service」を作成する必要がありますのでご注意ください。
Speech service作成とその注意点
Azureリソースは通常Azureポータルで作成しますが、今回の「Speech service」はSpeech Studio上で作成できます。
アバターの画像のところから更に下にスクロールしてもらうと以下のように「1.Speechリソースの選択」という箇所がありますので、そこの「音声リソースの作成」をクリックします。
すると以下のような「音声リソースの作成」ダイアログが表示されますのでそこに必要事項を入力します。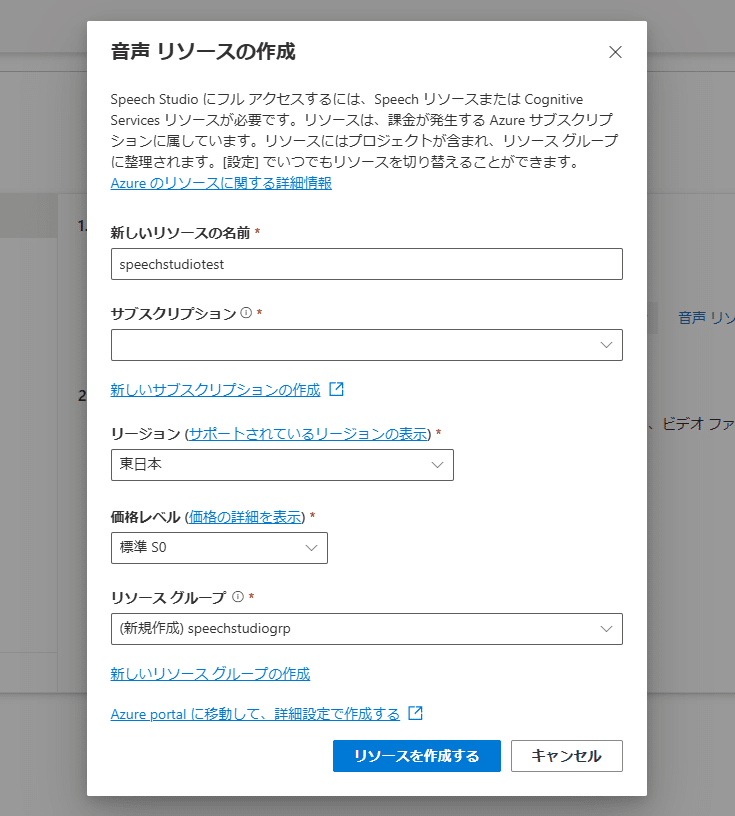
各入力項目の説明と共に注意点を幾つか書いておきます。
新しいリソースの名前:Speech serviceの名前
サブスクリプション:既に作成済みであればそのサブスクリプションを選択。必要であれば「新しいサブスクリプションの作成」で作成
リージョン:何でもOKではなく、以下のリージョンから選択する必要があるのでご注意ください
West Europe, West US 2, Southeast Asia, South Central US, Sweden Central, North Europe, East US 2
価格レベル:これも「標準 S0」を選択してください。「F0 無料」も選択し、作れるのですが、実行できない罠があります。。
リソースグループ:Azureサブスクリプション上のリソースグループを選択もしくは新規作成
このリージョンや価格レベルを良く調べずに作成してしまったがために、私は2、3回Speech serviceを作り直す羽目になりましたので皆様もご注意ください。。
テキスト読み上げ及びビデオの作成
Speech serviceを作成できましたので最初のアバターの箇所に戻ります。
アバターの画像の下に色々とリンクやプルダウンがあり、更にその下にテキストボックス(以下青枠部分)があります。ここに入力された文言をアバターが読み上げてくれます。

実は若干このUIが使いづらく、アバターをちゃんと選択していないと「オーディオの再生」ボタンやテキストボックスが入力不可の状態となりまして、一瞬パニックになってしまいました。私だけかもですが、試されるかたは頭の片隅にでも置いておいていただければと思います。
また、このテキストボックス内ではリターンキーを受け付けません。
色々と編集が大変なので、あらかじめテキストエディタで文章を作成し、それを貼り付けることをお勧めします。
読み上げてもらうテキストなのですが、前回同様当社ホームページより、以下の部分を読み上げてもらおうと思いますので丸々コピーします。

そしてテキストボックスに貼り付けます。

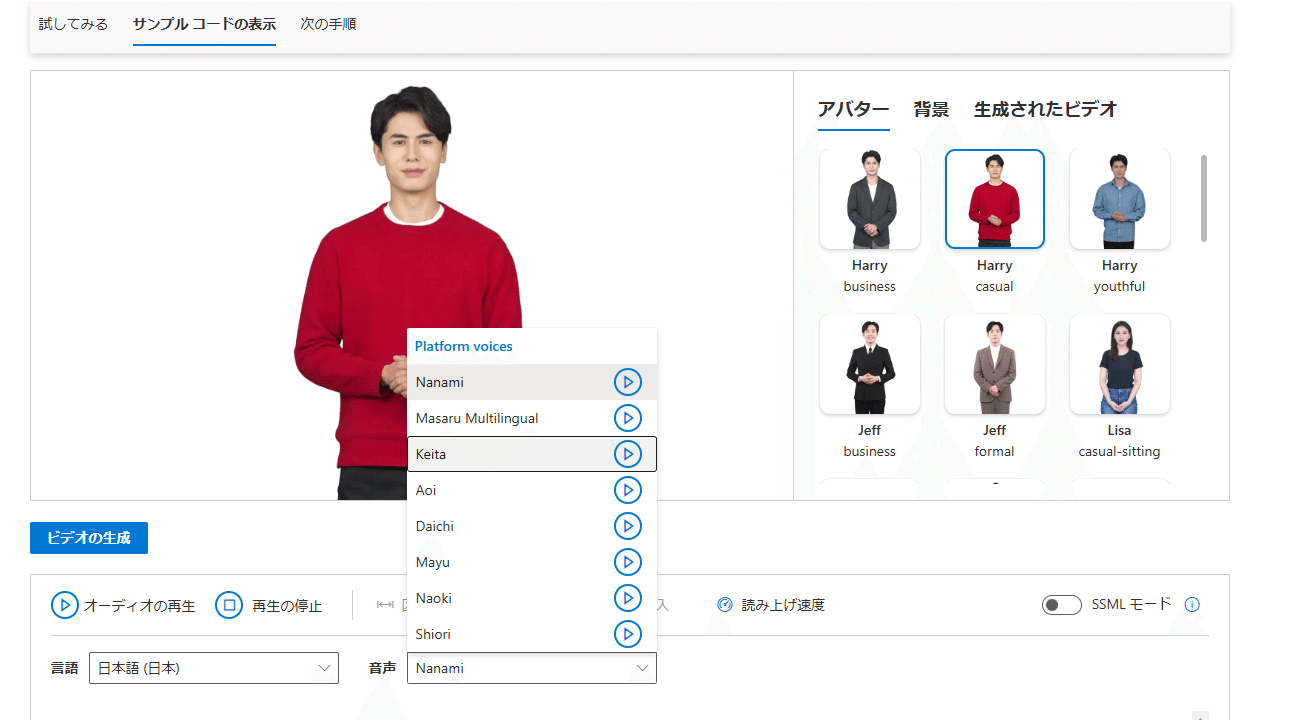
また、どちらが先でもよいのですが、テキストボックス上部の「言語」と「音声」を希望の言語にしておいてください。音声はとりあえず女性の名前である「Nanami」がデフォルトになっているようなのでそのままにします。

これでいきなりビデオの作成を行ってもよいのですが、試しにテキストボックス上部の「オーディオの再生」ボタンをクリックし、文章が正しく読まれていることを確認します。
若干イントネーションの不自然さもありますが、ちょっと前までのこういったテキスト読み上げサービスのような「いかにも機械が話している」感は無くなり、だいぶ自然な話し方になったと思います。
調整
問題無ければビデオの作成に移るのですが、もし音声に対して調整を行いたい場合は以下のような選択肢があります。
・音声

「音声」のプルダウンを選択すると上のように色々と選択肢があります。今回女性のアバターを選んでいますので「Nanami」「Aoi」「Mayu」「Shiori」が選択肢になると思います。幼い感じの声もあり、フォーマルな感じの声もあり、実際に聞いてみて適切な音声を選んでみてください。
・区切りの挿入
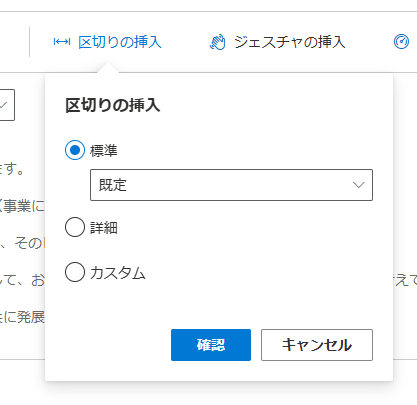
文章の区切り部分のインターバル、長さを設定できます。
・ジェスチャの挿入
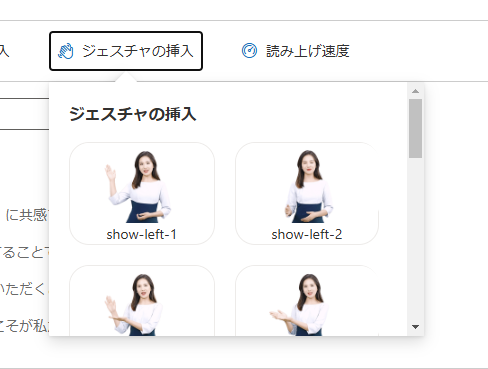
文章を読み上げに合わせてアバターがそれとなく動いてくれるのですが、その動きを指定できます。
・読み上げ速度

その名の通り、読み上げるスピードを設定できます。「×1」から始まり、×0.99、×0.98、もしくは×1.01、×1.02といった形でかなり細かく設定可能です。
ビデオの生成
読み上げ方が問題無ければ、いよいよビデオの作成となります。
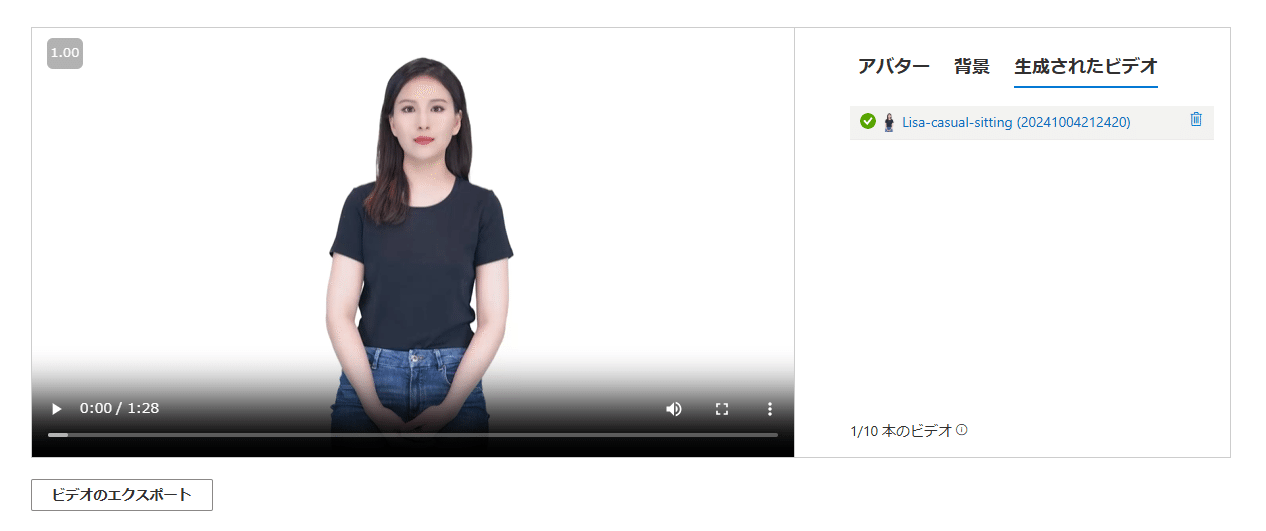
「ビデオの生成」をクリックすると以下のような表示になり、ビデオの生成が行われます。

生成の時間ですが、文章の長さにもよるものの、「あっという間」とはいかず30秒~1分ぐらいはかかりました。
生成が終わりましたら、アバターの左下、「ビデオのエクスポート」をクリックします。
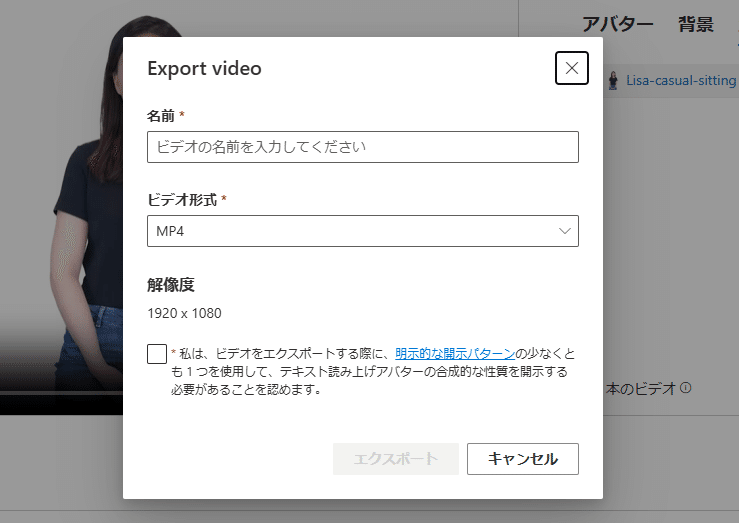
すると以下のような「Export video」ダイアログが表示されますので、ビデオファイル名を入力し、エクスポートします。
ダウンロードできたら、そのファイルを実行してみます。
以下の内容は画像なので申し訳ないのですが、指定したテキストを身振り手振り交えてしゃべってくれます。
身振り手振りが加わるとより自然な感じになりますし、口の動きも極力テキスト内容に合わせてくれているように思われます(例えば母音が「う」や「え」の発音でそのタイミングに合わせた口の形になっているように見えます)。

また、最初の画面に既に表示されていましたので皆様お気づきかと思いますが、アバターは様々な種類が用意されています。
男性のアバターも声質含め色々用意されていまして、これも非常に良い出来でした。
最後に
以上が「テキスト読み上げアバター」機能をざっと試してみた結果になります。
ひと昔前もこういった読み上げサービスというのは存在しており、実際に試した覚えもあるのですが、プログラミングが必要であるためにそのサービスの購入手続きから始まり、APIキーを取得して。。といった形で今回のように5~10分で試せるものではありませんでした。
しかも当時はかなりイントネーションがおかしく、それを考えると素晴らしい進歩だなと思います。
ただ、今回は非常に平易な文章だったため、特に読み間違えはありませんでしたが、専門用語等は事前にひらがなに変換するといった準備は必要になると思います。
この機能、トレーニング資料や製品紹介等に利用できそうですし、以前このブログでも扱ったアクセシビリティの向上にも期待できます。
今年の9月にGAとなったばかりのこの機能、Azureサブスクリプションが必要となりますが、是非皆さまもお試しください。