こんにちは。吾郷 Microsoft Azure 機械学習系サービス 前回の記事
開発環境
https://docs.microsoft.com/en-us/bot-framework/dotnet/bot-builder-dotnet-quickstart Bot × Recommendations APIを試してみたい。~Bot Framework編~
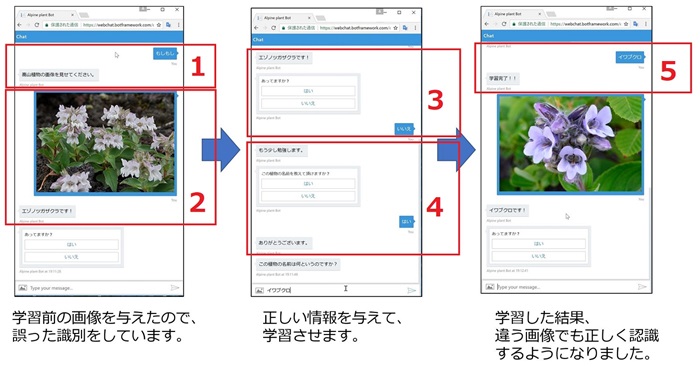
完成イメージ
ちなみに、Custom Vision Service の Train の実行条件に、タグ毎に5枚以上の学習データが必要ですが、
実装の説明
プロジェクトの作成
ユーザが見せてくれた画像の識別 MessageReceivedAsyncで実装しています。 処理の概要は、こんな感じです。
画像識別だけなら、Key は Prediction Key を使います。
画像の識別は以下のコード1行です。
外れていた場合に学習するために、識別用に登録した画像のIDを覚えておきます。
あってるかユーザに確認する。
画像の学習
画像の学習に関連する処理を行う場合は、Training Key を使います。
まずはタグの有無をチェックしてタグがなければ登録します。
識別したときに登録された画像IDを取得します。
画像IDとタグの紐づけをします。
Train を実行します。
さいごに
using System;
using System.Threading.Tasks;
using Microsoft.Bot.Builder.Dialogs;
using Microsoft.Bot.Connector;
using Microsoft.Cognitive.CustomVision.Models;
using Microsoft.Cognitive.CustomVision;
using System.Net.Http;
using System.Threading;
namespace botcvs.Dialogs
{
[Serializable]
public class RootDialog : IDialog
{
public Task StartAsync(IDialogContext context)
{
//context.Wait(MessageReceivedAsync);
context.Wait(MessageHelloAsync);
return Task.CompletedTask;
}
private async Task MessageHelloAsync(IDialogContext context, IAwaitable result)
{
var activity = await result as Activity;
if (activity.Type == "message")
{
if (activity.Text.Length > 0)
{
await context.PostAsync($"高山植物の画像を見せてください。");
context.Wait(MessageReceivedAsync);
}
}
}
private async Task MessageReceivedAsync(IDialogContext context, IAwaitable result)
{
var activity = await result as Activity;
if (activity.Type == "message")
{
// 画像をつけてもらえたか確認
if (activity.Attachments?.Count != 0)
{
// Custom Vision API を使う準備
var predictionCred = new PredictionEndpointCredentials("[PREDICTON KEY]");
var predictionEp = new PredictionEndpoint(predictionCred);
var projctId = new Guid("7c0feea9-f34f-40cd-a99f-4f282c945011");
// 送られてきた画像を Stream として取得
var photoUrl = activity.Attachments[0].ContentUrl;
var client = new HttpClient();
var photoStream = await client.GetStreamAsync(photoUrl);
// 画像を判定
var cvResult = await predictionEp.PredictImageAsync(projctId, photoStream);
// 一番高いスコアを取得
var tag = "";
var score = 0.00;
foreach (var item in cvResult.Predictions)
{
if (score < item.Probability)
{
score = item.Probability;
tag = item.Tag;
}
}
var msg = "";
if (score >= 0.8)
{
// scoreが0.8 を超えてたら自信満々に回答
msg = tag + "です!";
}
else
{
// scoreが0.8 未満は半疑問形
msg = tag + "かな?";
}
await context.PostAsync(msg);
// 後で学習するときに向けてIDを抑えておく
context.ConversationData.SetValue("PredictImageId", cvResult.Id);
// 確認のメッセージ
PromptDialog.Confirm(
context,
AfterMessageAsync,
"あってますか?",
"???",
promptStyle: PromptStyle.Auto);
}
else
{
// 画像を再度要求
await context.PostAsync($"高山植物の画像を見せてください。");
context.Wait(MessageReceivedAsync);
}
}
}
public async Task AfterMessageAsync(IDialogContext context, IAwaitable argument)
{
var confirm = await argument;
if (confirm)
{
await context.PostAsync("よかったです。また画像を見せてくださいね。");
context.Wait(MessageReceivedAsync);
}
else
{
await context.PostAsync("もう少し勉強します。");
PromptDialog.Confirm(
context,
AfterLearningAsync,
"この植物の名前を教えて頂けますか?",
"この植物の名前を教えて頂けますか?",
promptStyle: PromptStyle.Auto);
}
}
public async Task AfterLearningAsync(IDialogContext context, IAwaitable argument)
{
var confirm = await argument;
if (confirm)
{
await context.PostAsync("ありがとうございます。");
await context.PostAsync("この植物の名前は何というのですか?");
// 学習用のダイアログに遷移
context.Wait(LearningMessageReceivedAsync);
}
else
{
await context.PostAsync("そうですか。。。残念です。");
await context.PostAsync("また、素敵な植物の画像を見せてくださいね。");
context.Wait(MessageReceivedAsync);
}
}
private async Task LearningMessageReceivedAsync(IDialogContext context, IAwaitable result)
{
var activity = await result as Activity;
if (activity.Text.Length > 0)
{
// Custom Vision API を使う準備
var trainingCredentials = new TrainingApiCredentials("[TRAIN KEY]");
var trainingApi = new TrainingApi(trainingCredentials);
var projctId = new Guid("7c0feea9-f34f-40cd-a99f-4f282c945011");
Guid newTagGuid = Guid.Empty;
try
{
// すでにあるタグかチェック
var taglist = trainingApi.GetTags(projctId);
foreach (var tagname in taglist.Tags)
{
if (tagname.Name == activity.Text)
{
newTagGuid = tagname.Id;
break;
}
}
// タグIDが設定されていない場合は、タグを作成する。
if (newTagGuid == Guid.Empty)
{
var newTag = trainingApi.CreateTag(projctId, activity.Text);
newTagGuid = newTag.Id;
}
// 学習済の画像のIDを取得する。
var predictionId = context.ConversationData.GetValue("PredictImageId");
// 画像とタグを組み合わせて登録する
var imageIdTags = new ImageIdCreateBatch();
imageIdTags.TagIds = new[] { newTagGuid };
imageIdTags.Ids = new[] { predictionId };
var retCreatetagu = trainingApi.CreateImagesFromPredictions(projctId, imageIdTags);
if (retCreatetagu.IsBatchSuccessful == true)
{
// Trainを実行する。(タグの画像が5枚以下の場合はエラーとなるけど、ひとまず無視)
var iteration = trainingApi.TrainProject(projctId);
while (iteration.Status == "Training")
{
Thread.Sleep(1000);
// Re-query the iteration to get it's updated status
iteration = trainingApi.GetIteration(projctId, iteration.Id);
}
iteration.IsDefault = true;
trainingApi.UpdateIteration(projctId, iteration.Id, iteration);
await context.PostAsync("学習完了!!");
context.Wait(MessageReceivedAsync);
}
else
{
await context.PostAsync("** タグの最低数5枚に達していないのでTrainできませんでした **");
context.Wait(MessageReceivedAsync);
}
}
catch (Exception ex)
{
//await context.PostAsync(ex.Message);
context.Wait(LearningMessageReceivedAsync);
}
}
else
{
await context.PostAsync("もう一度教えてください。");
context.Wait(LearningMessageReceivedAsync);
}
}
}
}