こんにちは。
コンサルティング & テクノロジー部の上坂です。
この記事はネクストスケープ クラウド事業本部のAdventCalenderの24日目です。
DeepLearningやっていると、学習にとても時間がかかってしまって気軽にTry&Errorできないのが辛い所ですよね。GPUのパワーに頼るにしてもオンプレでは限界があるし、クラウド上のIaaSでDeepLearning環境を作るとしても、ハイパワーなIaaS1台で学習させるなら特に難しいことはありませんが、複数台でクラスタ構成組むとなるとそれだけで一苦労です。
2017年5月10日、MicrosoftのBuildというイベントでAzure Batch AI Trainingというサービスが発表されました。このサービスはAzure Batch、という名前から推測できる通り、Azure上でクラスタ環境を組んでくれるものです。これを使って、学習スピードを大幅に短くすることができるかもしれません。現在は名称がAzure Batch AI Service、もしくはAzure Batch AI、となったようです。

このAzure Batch AI、まだPreviewではありますが、きっとGA後はDeepLearningをAzureで実行する時に最も使用頻度が高いリソースになるでしょう。 今日はこの Azure Batch AIについて調べた内容と、実験した結果を書いてみたいと思います。
公式ページのドキュメントではAzure CLI2とPythonによる構築・実行の方法しか説明がありませんが、Azure Portalでも構成・実行は可能です。公式ページに先駆けて、Azure Portalで構成・実行してみましょう。
Azure Batch AI Overview(概要)
Azure Batch AIはVMでクラスタが構成されます。裏側では恐らくVMSS(Virtual Machine Scale Set)が使用されているのだと思われます。通常VMSSによるクラスタ構成の場合、クラスタ上で起動するアプリケーションのセットアップは予めセットアップ済みのイメージを使うか、もしくは起動後にセットアップスクリプトを動かすかのどちらかですが、Azure Batch AIでは現在のところ次の二通りが用意されています。
- MacketPlaceに用意されているデータサイエンス仮想マシンを使用する
- まっさらなOSにDockerを構築する
どちらを使用するとしても、現在のところOSはUbuntu16.04-LTSのみです。 Azure BatchのVMとしてデータサイエンス仮想マシン(Data Science Virtual Machine。以降DSVMと表記)を使用する場合は、DSVMにインストールされているDeepLearning用のフレームワークであれば、実行できることになります。
- CNTK
- TensorFlow
- Theano
- Chainer
- Keras
- Caffe
- Caffe2
などが使用できます。
Dockerを使用する場合、URLを指定しなければDockerHubからダウンロードしてセットアップしてくれます。URLとクレデンシャルを指定すれば、Private RegistoryからImageをPullして自動的にセットアップしてくれます。
システム構成図
Azure Batch AIでは、各クラスタが参照するFileServerが必要となります。FileServerにデータやスクリプトを配置して、それを各クラスタから見に行く訳ですが、FileServerの構築は面倒です。Azure Batch AIではFileServerの他に、Azure StorageのBlobのFile Shareを使用することができます。
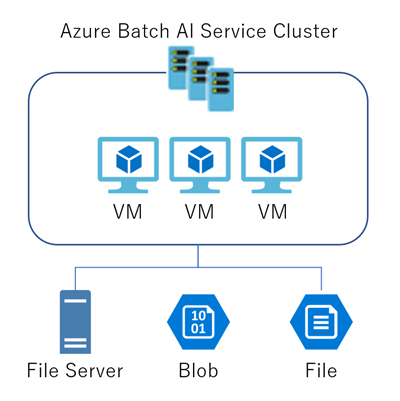
リソース構成図
Azure Batch AIは、それ単体ではクラスタを構成するリソースとなります。OSはDSVMを使うのか、まっさらなUbuntuを使うのかを選び、参照するFileServer(もしくはStorage)をマウントする設定をします。
DeepLearningの学習を行うためのリソースはJobです。Jobでは以下の情報を設定します。
- ノード数
- 使用するフレームワーク
- FileServerのどこに入力データやスクリプトがあるのか
- FileServerのどこに出力するのか
- (オプション)使用するDockerイメージ
- (オプション)Job起動前の実行コマンド
- (オプション)環境変数
Jobは作成するとすぐに起動します。作成したJobに対してRunコマンドを発行する、という面倒なひと手間はありません。
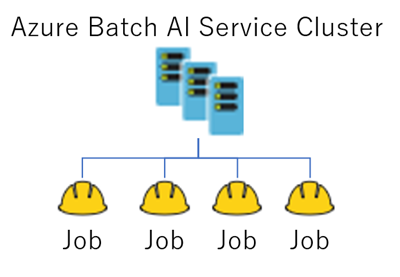
Azure Batch AIを使う
ではAzure Batch AIを使ってみましょう。
File Shareを作る
Azure Batch AIを構成する時、どこのFileServerをなんという名前でマウントするのかを指定する必要があります。そのため、先にFileServerを構築しなければなりません。今回はFileServerではなくStorageのFileShareでやります。次の手順で作成しておいてください。
- Storageアカウントを作る
- FileShareを作る
- ディレクトリを作る
ここで次の情報をテキストエディタにメモっておいてください。後ほど使用します。
FileShareのURLは
https://<Storage Account>.file.core.windows.net/<FileShare>
このような形式です。ディレクトリ名は含まないでください。
Azure Batch AIを作る
Azure Portalで新規リソースを作る画面を表示してください。リソースの検索をする場合は「Batch AI Service」、もしくは「Batch AI」で検索します。先頭にAzureとつけるとリソースが出てきてくれませんので注意しましょう。
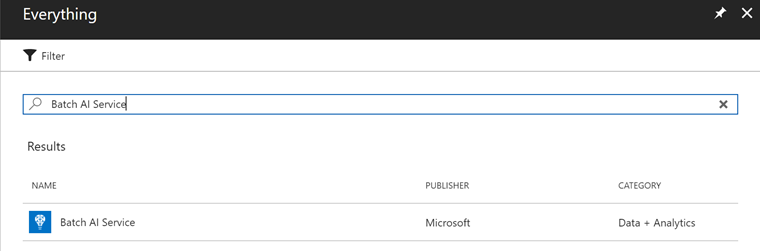
Cluster、Job、File Serverのどれを作るのかを選択するダイアログが表示されます。え、ここでFileServer作れるの?すごい便利!と思って試してみましたが、なんどやっても私は失敗しました。もうちょっと待つとうまく作れるようになるでしょう。Clusterを選びます。
では設定していきましょう。注意点がいくつかあります。
- Locationは現在のところEastUSを選んでおくのが無難です。恐らく他のリージョンはまだ対応していません。
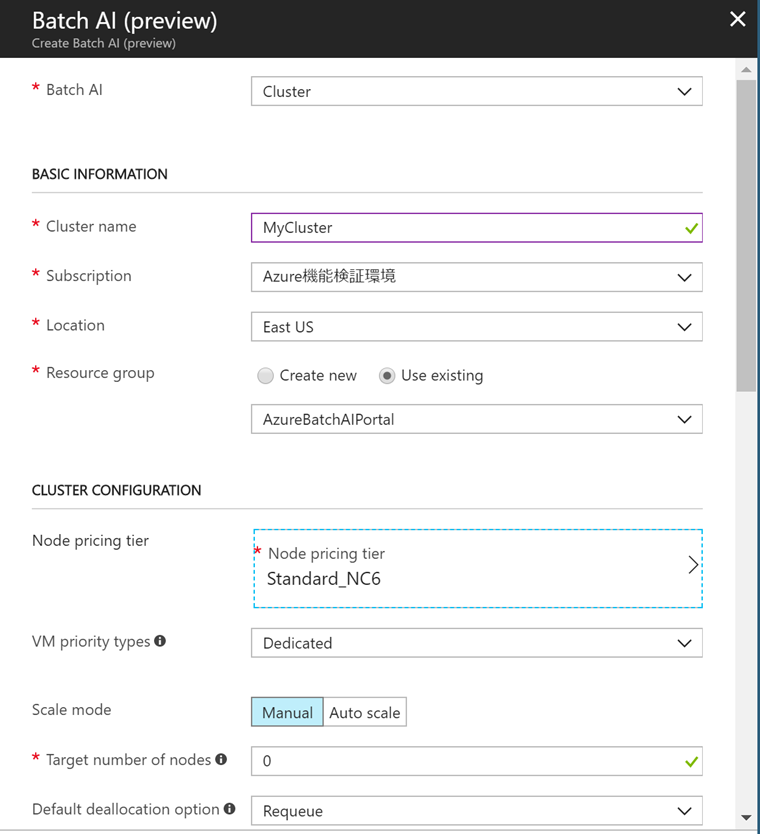
- リソースグループはこの画面で新規作成しないで、既存のものを選んでください。新規作成だとなぜかVMのSKUが選べません。
- NODE SETUP - MOUNT VOLUMESを Enableにして、Azure file share referencesに、先ほど作ったFileShareを設定します。
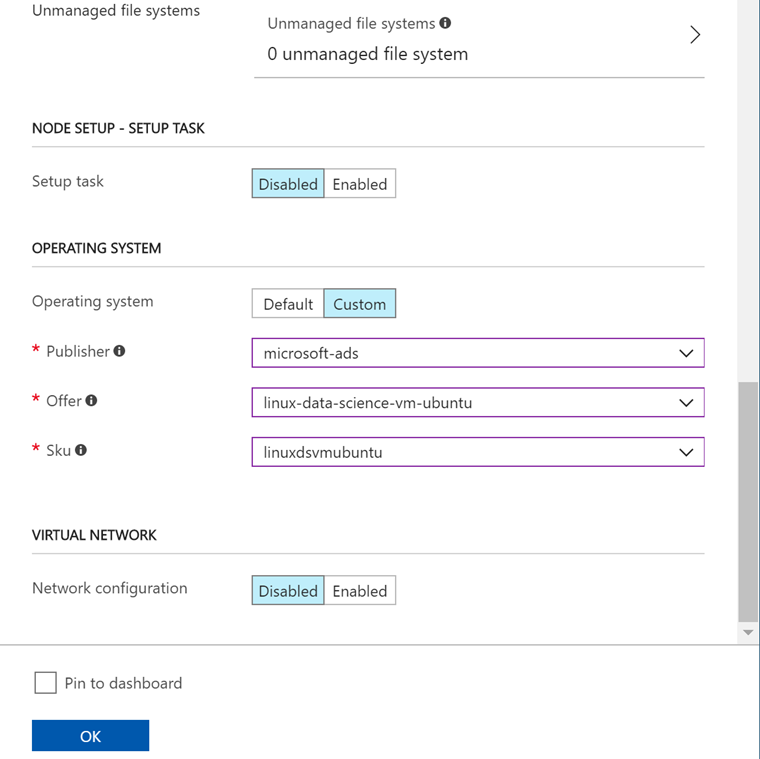
(FileShareの設定画面で、Azure file urlには先ほどメモしたFile ShareのURLをセットする) - OPERATING SYSTEMを Enableにして、Customを選びます。
(Publisherで「Canonical」を選ぶとまっさらなUbuntu、「microsoft-ads」を選ぶとDSVM)
今回、OSはDSVMにしました。その他の項目は好きに設定していただいて構いません。OKボタンをクリックして作成します。作成にそれほど時間はかかりません。1分しないぐらいで作成できます。設定画面の画像を貼り付けておきます。

Jobを作成(起動)する
公式ページではTenforFlowとCNTKの説明しかありませんが、Azure Batch AIの Github には他にも説明があります。
今回はこちらの様々なレシピを参考にしながら、Docker+Keras+Tensorflowで動かしてみましょう。先ほど作成したClusterのOverview画面の上部にあるAdd batch AI jobをクリックします。

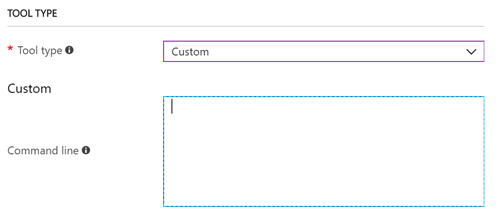
Job作成画面が開きます。設定していきましょう。Job名などの説明不要なところは飛ばしまして、TOOL TYPEを説明します。TOOL TYPEでは、どのFrameworkを使用するのかを選択します。残念ながらKerasはまだサポートされていないので、Customを選択します。現れたCommand LineのTextareaにコマンドを書いていくのですが、その前に入出力の環境変数を作っておきます。
環境変数の作成はADDITIONAL INPUTSで行います。この設定が重要です。まず、Stdout/err Path Prefixで、$AZ_BATCHAI_MOUNT_ROOT/<moutnName>を選択します。<mountName>には、Clusterを作る時にFile Shareのマウント場所として指定した名前が入っているはずです。
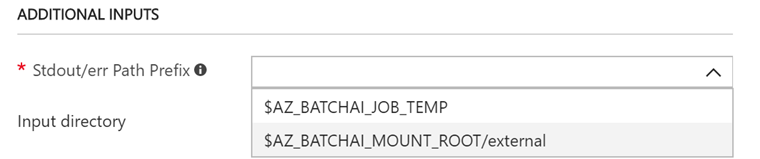
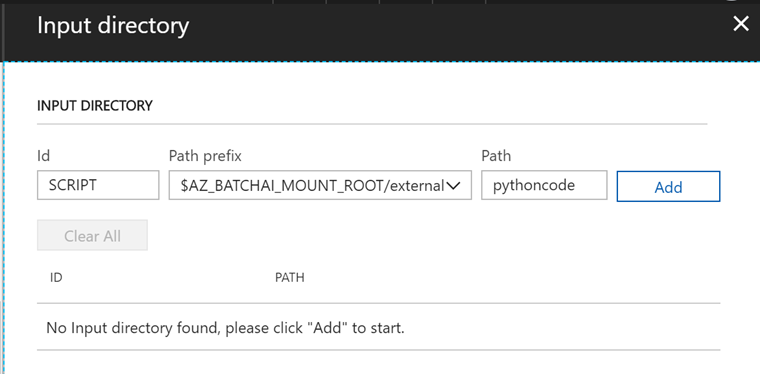
次にInput directoryの環境変数を作成します。
IDとPath prefixと、Pathの3つの入力エリアがありますが、適当に名前を決めてはいけません。この3つの変数に入力すると、次のような環境変数と値が作成されます。
$AZ_BATCHAI_INPUT_<ID>=$AZ_BaTCHAI_MOUNT_ROOT_<mountName>/<path>
例えば、IDにSCRIPT、Pathにpythoncodeと入力すると、 $AZ_BATCHAI_INPUT_SCRIPTという環境変数が作成され、その値は$AZ_BaTCHAI_MOUNT_ROOT_<mountName>/pythoncode、となります。
この$AZ_BATCHAI_INPUT_SCRIPTを使うことで、FileShareに配置するコードやデータにアクセスするコマンドを書くことが可能になる訳です。
全く同様にして、今度はOutput directoryの環境変数を作成します。これは、通常学習済みのモデルをExportする先として使用します。

出力先のDirectoryPathは、実行するPythonコードに引数として渡す必要があります。Pythonコードでは、引数を受け取って、モデルを保存するコードを実装しなければなりません。
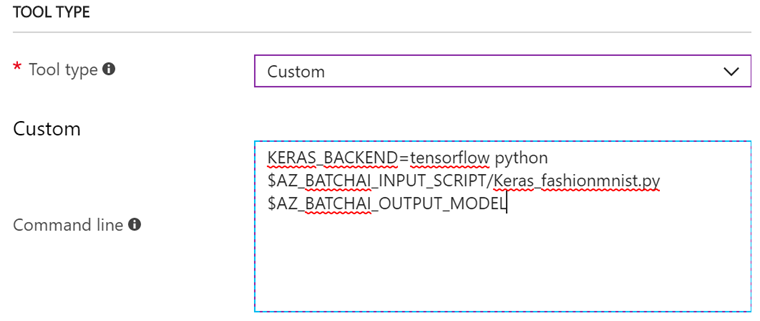
さて、ここで一度TOOL TYPEに戻ります。さきほどCustomを選択しましたが、CommandLineにはまだ何も入力していません。Command Lineには次のように入力します。
KERAS_BACKEND=tensorflow python $AZ_BATCHAI_INPUT_SCRIPT/Keras_fashionmnist.py $AZ_BATCHAI_OUTPUT_MODEL
環境変数を使って、Pythonコードを指定しています。Keras_fashionmnist.pyはまだ作っていないPythonコードです。後ほど作成して、FileShareにアップロードします。
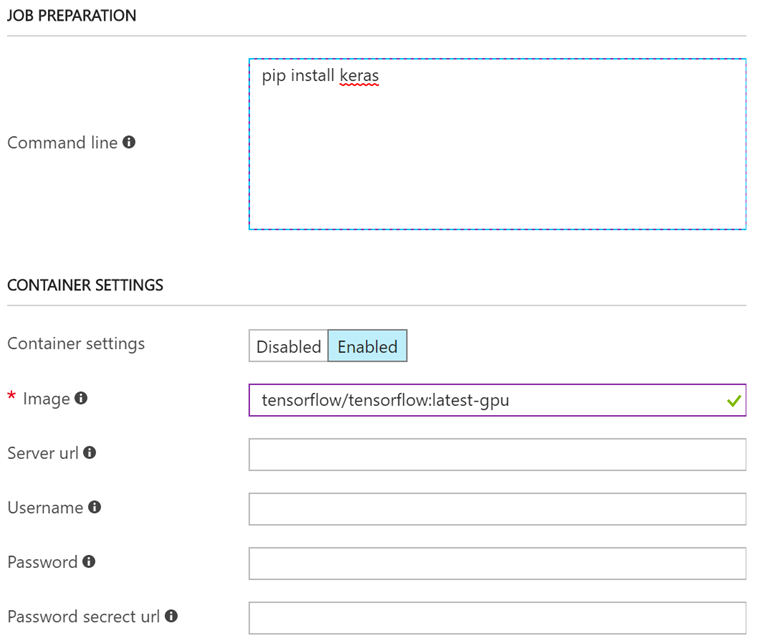
次の項目はCONTAINER SETTINGSです。Dockerの設定をします。Enabledをクリックして、Imageに
tensorflow/tensorflow:latest-gpu
と入力します。DockerHubにある、TenforFlowの公式イメージのうち、GPU対応している最新もの、という意味です。その他の項目はDockerHub以外のRegistryを使用する場合です。
一つ上のJOB PREPARATIONでは、Job起動前に実行させたいコマンドを記載することができます。とはいっても、今回はToolTypeがカスタムなのでそちらのCommand Lineに記載しても同じ結果になりますが、お作法として環境構築のコマンドはJOB1 PREPARATIONに記載しましょう。
pip install keras
Tensorflowの公式イメージにはKerasが入っていないので、ここでインストールしています。
さて、最後にOKボタンをクリックする前に、PythonコードでFashion MNISTを実装したものをFileShareにアップロードします。OKボタンをクリックすると、JobがSubmitしますのでまだクリックしないでください。
Fashion MNISTはMNISTよりも認識が難しくなっています。MNISTのようにすぐにaccuracyが高くなってしまうようなことがないため、EarlyStoppingするまでにそれなりにEpoch数を回すことができます。なにかを試す時にはMNISTよりも良いデータです。Fashion MNISTを認識するコードではありませんが、全くのゼロから実装するのは面倒なので、RecipeにあるMNISTを学習するコードを拝借して修正しましょう。
https://github.com/Azure/BatchAI/blob/master/recipes/Keras/Keras-DSVM/mnist_cnn.py
こちらのコードを修正します。Fashion MNISTに対応するための修正箇所はたったの2か所です。
- from keras.datasets import mnistを、from keras.datasets import fashion_mnistにする
- mnist.load_data()を、fashion_mnist.load_data()にする
簡単ですね。次に、せっかくですから作成したモデルを出力するコードを実装しましょう。次のコードをコードの上のほうに追加します。
- import sys
- import os
- model_path = sys.argv[1]
このsys.argv[1]で、Pythonコードの外部から渡された出力先のDirecotryを受け取っています。モデルの出力を実装します。一番最後に次のコードを追加します。
model.save(os.path.join(model_path, "Keras_MNIST.h5"))コード全体をアップしておきますので、よろしければご利用ください。
作成したPythonコードのファイル名をKeras_fashionmnist.pyにして、File ShareのDirectoryにUploadしておいてください。さきほど、Job作成画面でToolTypeのCommandLineに、Keras_fashionmnist.pyというPythonファイルを起動する内容が入っていた為、ファイル名が違うと動きません。
ここまでできたら、さきほどのJob作成画面のOKをクリックです。
じーっとしばらく待つと、処理が始まりますが、とにかく最初は時間がかかります。VMを立ち上げて、DockerをPullして設定して・・・なので遅いのです。
Cluterの状態は、Start->Queued->Running->Endの4つの状態を遷移します。どうやらQueuedの間はVMを立ち上げている時間のようです。Runningまでいくと、stdout/errに出力が始まりますので、標準出力の出力先であるstdout.txtを注視することで処理状況をリアルタイムにみることができます。ファイルをいちいちダウンロードしているとつらいので、Azure CLIのコマンドで出力をStreamで受けてみましょう。次のコマンドです。
az batchai job stream-file -g <ResouceGroupName> --job-name <JobName> --output-directory-id stdouterr --name stdout.txt
最後のstdout.txtをstderr.txtにすると、エラー、警告を見ることができます。
最後まで無事に正常終了するとこのような画面になります。
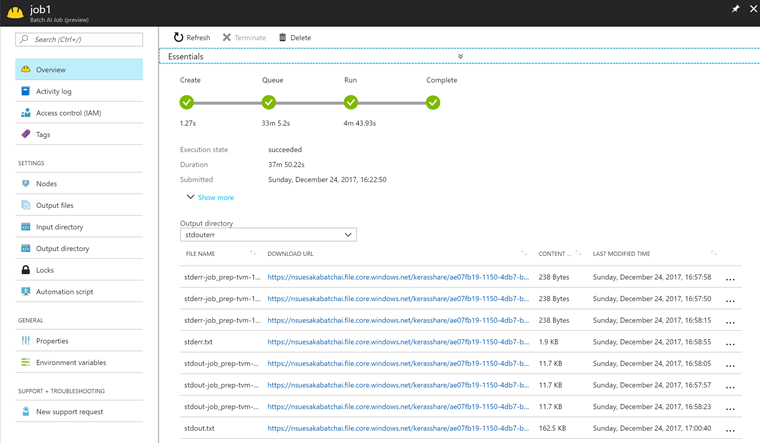
うまくKerasのモデルは無事に出力されているかを確認しましょう。 Output directoryをMODEL(出力の環境変数を作った時に命名したID)にすると、ModelへのURLが表示されます。

正しく出力されているかはこのh5ファイルを別途読み込ませて動かしてみないとわかりませんが、今回は出力されていることを確認するところまででOKとします。
最後に
Azure Batch AI、まだまだ使い勝手の向上が望まれますが、それでも今の時点でかなり使いやすいものだな、と思いました。今回はSingleNodeでしたので分散環境とは言えません。分散環境として動かすためには、フレームワーク固有の実装が必要です。いずれ気が向いたらブログに書こうと思います。Azure PortralでAzure Batch AIはかなりわかりやすくて優しいのですが、それでも改善してほしいなぁという点がいくつもありました。ちなみに私が思った改善要望は以下です。
- Azure Batch AIの作成画面で、Storageの作成、FileShareの作成、Directoryの作成まで指定できるようにしてほしい
- Jobの作成画面で、InputとOutputの指定をもっとGUIでできるようにしてほしい
- JobのJsonだけをImportとExportできるようにしてほしい
- az batchai job stream-fileによる出力を、ファイルをクリックしたら実行してほしい
- Clusterの作成画面で、リソースグループを新規作成にするとNodeのPricing Tierが選択できない(バグ?)
Portalの改善要望を出したことがないのですが、確かPortalからできるはずなので、後でやってみたいと思います。(日本語じゃダメかな?)
さて、ネクストスケープクラウド事業本部のAdventCalenderは明日で最後です。どんなネタかな?お楽しみに!